
本文献给跟我一样虽然屁都不会但是谜一样的自信地投了软开岗位的旁友们
希望我们都能获得尘世间的幸福
1. 茴字有几种写法(排序啦是排序
参考Boblim的博客
| 排序方法 | 时间复杂度(平均) | 空间复杂度 | 稳定性 | 原理 |
| :——: | :—————-: | :——–: | :—-: | :———————————————————– |
| 冒泡 | O(n²) | O(1) | 稳定 | 在扫描过程中两两比较相邻记录,如果反序则交换,最终,最大记录就被“沉到”了序列的最后一个位置,第二遍扫描将第二大记录“沉到”了倒数第二个位置,重复上述操作,直到n-1 遍扫描后,整个序列就排好序了。 |
| 插入 | O(n²) | O(1) | 稳定 | 对于一个数组A[0,n]的排序问题,假设认为数组在A[0,n-1]排序的问题已经解决了。 考虑A[n]的值,从右向左扫描有序数组A[0,n-1],直到第一个小于等于A[n]的元素,将A[n]插在这个元素的后面。 |
| 归并 | O(nlogn) | O(n) | 稳定 | 采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案”修补”在一起,即分而治之)。 |
| | | | | |
| 选择 | O(n²) | O(1) | 不稳定 | 初始时在序列中找到最小(大)元素,放到序列的起始位置作为已排序序列;然后,再从剩余未排序元素中继续寻找最小(大)元素,放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 |
| 希尔 | O(nlogn) | O(1) | 不稳定 | 希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。 |
| 堆排 | O(nlogn) | O(1) | 不稳定 | 利用堆的性质来进行排序的 |
| 快排 | O(nlogn) | O(nlogn) | 不稳定 | 选一个数作为基准,双指针分别从前后两端遍历数组,当后指针比基准小且前指针比基准大时交换,直到相遇。把相遇位置的数与基准数做交换,继续快排二分后的两个数组。 |
| | | | | |
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
冒泡应该是讲的最多的?底下有个大概示意
例题:冒泡
1 | for (i = 0; i < len; i++){ |
理解了冒泡那么插入和选择也都很好理解和记忆
稍微进阶一点的记住快排的原理和实现
例题:快排实现
1 | 要点是选一个 前后各一个指针和它比大小 |
堆排也很重要但是我没记住(ntm
预留空位等我搞懂了再放
一个非常简陋的时间和空间复杂度计算方法
时间复杂度: 一层for循环就是n的一次方,两层嵌套就是n²,只算最高次的。用了二分法的就跟log有关系。
空间复杂度:用了额外空间就不是O(1)了,具体多少就看开了多少内存。
2. 数据结构
例题: C++中的容器都有哪些?map如何实现?红黑树是什么?
顺序容器:顺序容器有以下三种:可变长动态数组 vector、双端队列 deque、双向链表 list。
关联容器:关联容器有以下四种:set、multiset、map、multimap。关联容器内的元素是排序的。插入元素时,容器会按一定的排序规则将元素放到适当的位置上,因此插入元素时不能指定位置。
除了以上两类容器外,STL 还在两类容器的基础上屏蔽一部分功能,突出或增加另一部分功能,实现了三种容器适配器:栈 stack、队列 queue、优先级队列 priority_queue。
所有容器都有以下两个成员函数:
- int size():返回容器对象中元素的个数。
- bool empty():判断容器对象是否为空。
- begin():返回指向容器中第一个元素的迭代器。
- end():返回指向容器中最后一个元素后面的位置的迭代器。
- rbegin():返回指向容器中最后一个元素的反向迭代器。
- rend():返回指向容器中第一个元素前面的位置的反向迭代器。
- erase(…):从容器中删除一个或几个元素。该函数参数较复杂,此处省略。
- clear():从容器中删除所有元素。
- front():返回容器中第一个元素的引用。
- back():返回容器中最后一个元素的引用。
- push_back():在容器末尾增加新元素。
- pop_back():删除容器末尾的元素。
- insert(…):插入一个或多个元素。该函数参数较复杂,此处省略。
要访问顺序容器和关联容器中的元素,需要通过“迭代器(iterator)”进行。迭代器是一个变量,相当于容器和操纵容器的算法之间的中介。迭代器可以指向容器中的某个元素,通过迭代器就可以读写它指向的元素。从这一点上看,迭代器和指针类似。
1 | 容器类名::iterator 迭代器名; //正向迭代器 |
- advance(p, n):使迭代器 p 向前或向后移动 n 个元素。
- distance(p, q):计算两个迭代器之间的距离,即迭代器 p 经过多少次 + + 操作后和迭代器 q 相等。如果调用时 p 已经指向 q 的后面,则这个函数会陷入死循环。
- iter_swap(p, q):用于交换两个迭代器 p、q 指向的值。
| 容器 | 迭代器功能 |
|---|---|
| vector | 随机访问 |
| deque | 随机访问 |
| list | 双向 |
| set / multiset | 双向 |
| map / multimap | 双向 |
| stack | 不支持迭代器 |
| queue | 不支持迭代器 |
| priority_queue | 不支持迭代器 |
map以模板(泛型)方式实现,可以存储任意类型的数据,包括使用者自定义的数据类型。主要用于资料一对一映射的情况,map内部的实现过程是自建一棵红黑树,这棵树具有对数据自动排序的功能。在map内部所有数据都是有序的。
数组、链表和列表
数组的内存空间是连续的,链表在内存空间内是离散的
例题:反转数组/链表
变种包括k个一组反转链表,从m-n反转链表,两两反转链表均可leetcode刷题
反转数组:reverse;双指针交换
反转链表:指针前中后,换指向
栈stack、堆heap和队列queue
堆是priorityQueue
例题:括号匹配(栈的应用),堆排序(堆的应用),
例题:两个栈做一个队列
思路:入队列是把需要存的元素插入栈1;出队列是pop栈2中的元素,把栈1中的元素依次插入栈2(注意这一步栈2必须为空),pop栈2中的元素。
例题:两个队列做一个栈
思路:出栈,把元素依次尾插入队列1;把前序元素全头删然后尾插到队列2,把最后一个元素pop掉,以此类推。新插入的元素尾插在原本的队列后面,成为下一次最先被pop掉的。插入原则:保证一个队列为空,一个队列不为空,往不为空的队列中插入元素。
树、二叉树、红黑树、搜索树
树:
二叉树:一个父节点有两个子节点
红黑树:
搜索树:有序排列的树
哈希表hashmap的原理
这玩意我觉得非常之坑,用起来稀里糊涂的,但是消除时间复杂度又很好用显得你很专业
例题:Two Sum
1 | class Solution { |
例题:LRU缓存机制
1 | class LRUCache { |
5. 网络
IP报文分片
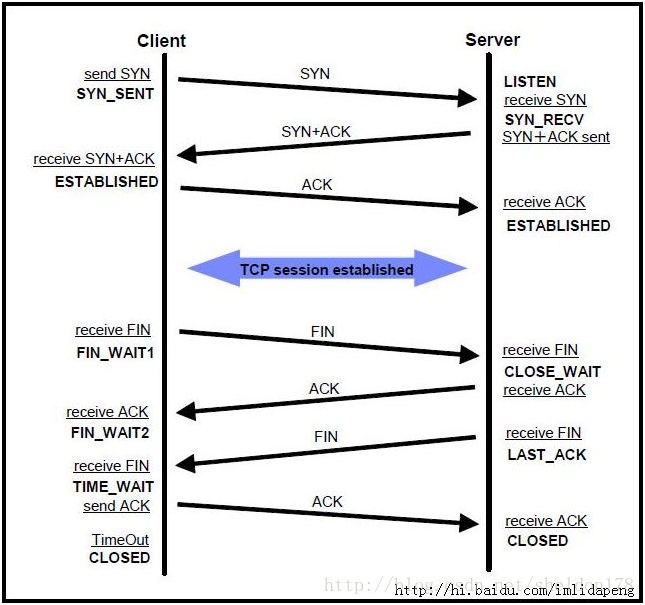
TCP的三次握手四次挥手
三次握手:Client-send SYN;Server-send SYN+ACK;Client-send SYN+ACK
四次挥手:Client-send FIN;Server-send ACK;Client-send FIN;Server-send ACK;
LISTEN:侦听来自远方TCP端口的连接请求;
SYN-SENT:在发送连接请求后等待匹配的连接请求;
SYN-RECEIVED:在收到和发送一个连接请求后等待对连接请求的确认;
ESTABLISHED:代表一个打开的连接,数据可以传送给用户;
FIN-WAIT-1:等待远程TCP的连接中断请求,或先前的连接中断请求的确认;
FIN-WAIT-2:从远程TCP等待连接中断请求;
CLOSE-WAIT:等待从本地用户发来的连接中断请求;
CLOSING:等待远程TCP对连接中断的确认;
LAST-ACK: 等待原来发向远程TCP的连接中断请求的确认;
TIME-WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认;
CLOSED : 连接已经关闭的状态;
例题:TCP连接半关闭,建立连接过程中的socket函数
例题:TCP头部数据里都有什么?标志位都有哪些?
例题:UDP为什么比TCP快?体现在哪些方面?TCP和UDP的区别?
HTTP1.0与1.1与HTTPS
例题:HTTPS的加密过程
例题:在搜索框输入域名到页面显示期间发生了什么
例题:RAP和DNS
6. 算法
递归
观察递归树,很明显发现了算法低效的原因:存在大量重复计算,比如 f(18) 被计算了两次,而且你可以看到,以 f(18) 为根的这个递归树体量巨大,多算一遍,会耗费巨大的时间。更何况,还不止 f(18) 这一个节点被重复计算,所以这个算法及其低效。
例题:二叉树深度、斐波那契数列
1 | int fib(int N){ |
明确了问题,其实就已经把问题解决了一半。即然耗时的原因是重复计算,那么我们可以造一个「备忘录」,每次算出某个子问题的答案后别急着返回,先记到「备忘录」里再返回;每次遇到一个子问题先去「备忘录」里查一查,如果发现之前已经解决过这个问题了,直接把答案拿出来用,不要再耗时去计算了。
一般使用一个数组充当这个「备忘录」,当然你也可以使用哈希表(字典),思想都是一样的。
1 | int fib(int N) { |
动态规划
递归的暴力解法 -> 带备忘录的递归解法 -> 非递归的动态规划解法